
Cloud technology powers our daily lives — from workplace applications to smart beds. Just like AI, it‘s the underpinning for many technologies that are now largely unnoticed by the average consumer. Over the past two weeks, two major outages helped us realize how deeply connected — and vulnerable — our systems have become.
First, on October 20, Amazon‘s AWS US-EAST-1 region went down, and it felt like the world stopped, in part, because AWS powers over 30% of the cloud market.

via Al Jazeera
Ironically, even 8Sleep users experienced outages. Why does a bed have a cloud dependency (and why does it send 16GB of data a month)? Because you can’t manage what you don’t measure. Part of that involves data, and another part involves updates and reporting. You can expect an increasing number of our household appliances to require cloud access.
Then, barely a week later, on October 29, Microsoft Azure experienced its own outage, affecting Microsoft 365, Kroger, Alaska Airlines, and even the Scottish Parliament.
A helpful reminder that when it rains, it pours, and even in the business of “uptime,” you should plan for downtime.
So, what happened?
Amazon AWS
The outage in the US-EAST-1 region (Northern Virginia) originated from a malfunction in an internal subsystem that monitors the health of network load balancers (within the Amazon DynamoDB API domain). This triggered Domain Name System (DNS) resolution failures, making key services unreachable or very slow.
AWS has 38 geographic regions (with plans to add 3 more). But US-EAST-1 was AWS’s first region, and is the largest, making it the default for documentation, new features, and cost-sensitive users. Additionally, some critical “global” AWS services have their control planes hosted in US-East-1, meaning an outage in this region can impact services in other regions too.
Microsoft Azure
Microsoft’s outage was triggered by an “inadvertent CDN configuration change” affecting the Azure Front Door (a global content-delivery / routing service), which resulted in widespread DNS and routing problems.
Both AWS and Azure experienced DNS issues, which anyone in tech should recognize as the most common point of failure in situations like this.
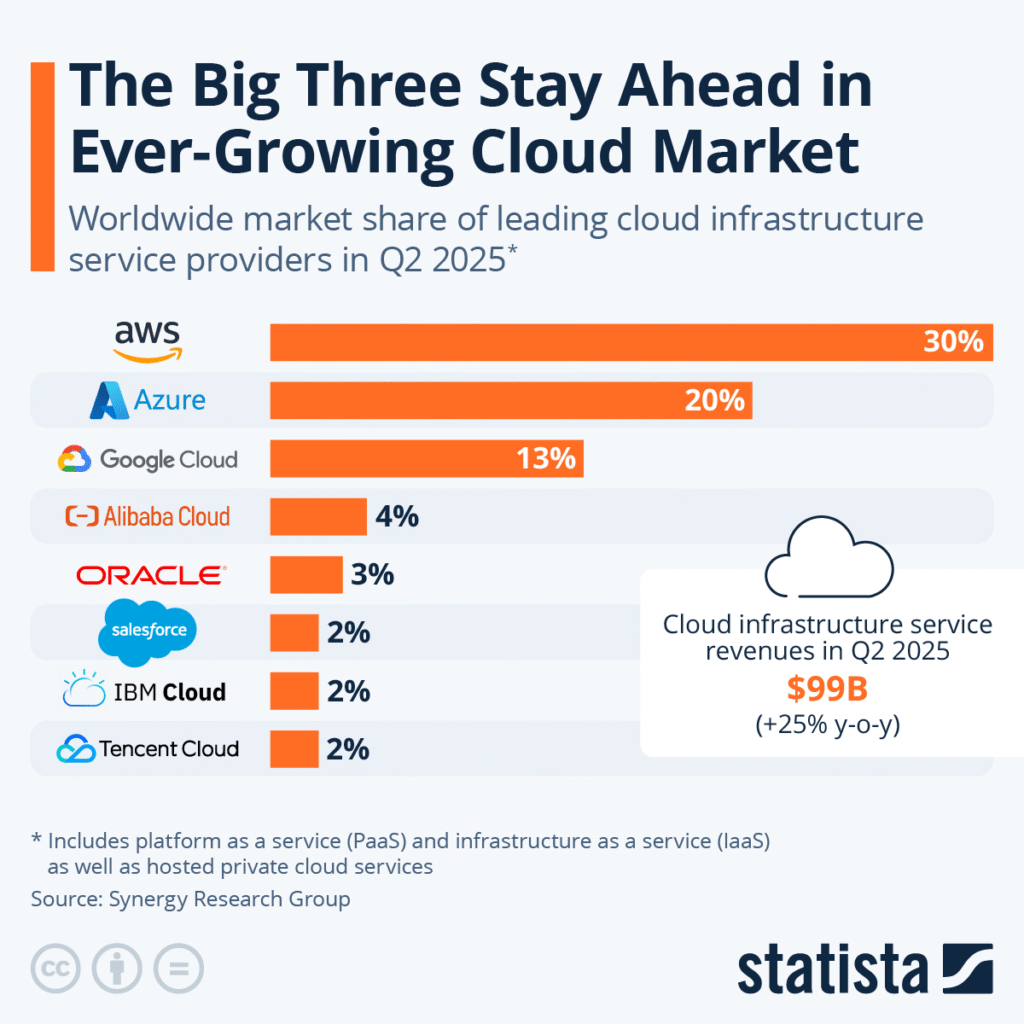
via Statista
But, since Amazon and Microsoft account for over 50% of cloud infrastructure, errors become especially noticeable.
Is Centralization the Issue?
To many, this seems like a call to break up these powers and spread responsibility.
“If a company can break the entire internet, they are too big …”
Not only is this not how the internet works, but it’s not how business works. Breaking up these providers would make it harder and more expensive for small businesses to compete. Access makes things cheaper.
As we discuss these global “utility” providers, it is beneficial to have a few key vendors. You don’t want it to be one. Then you get into monopoly territory. But, scale lowers cost. Most people understand this.
The reality is that, when compared to previous issues, Amazon has significantly improved its resiliency. They’ve also made efforts to lower the global dependence on US-EAST-1.
Before I go forward, it’s worth reminding people that the cloud is ultimately just a computer that you don’t own. Granted, it’s a very large computer with incredible infrastructure. But it is still a glorified computer. It will never be invincible and 100% faultless.
What Should I Learn From This Situation?
I am reminded of a great image from Randall Munroe and XKCD. It has been adapted to fit the current situation.
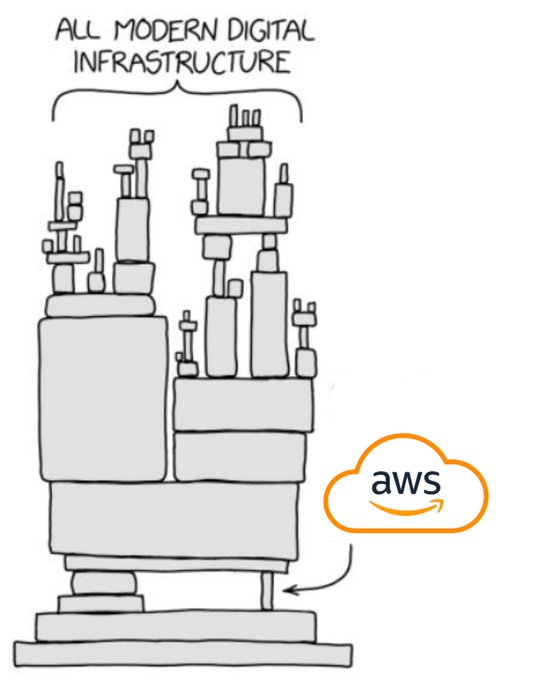
via XKCD
The reality is every system is fallible. Any sufficiently complex system will create bottlenecks and failure points.
The lesson isn’t decentralization, it’s redundancy.
One of the lessons a mentor taught me was that planning for failure is an important part of hoping for success.
It’s great to look toward the future and be proud of all that you’re doing things the right way. However, without a disaster recovery plan and redundancies for failures, you’ll eventually face consequences.
Without a plan, downtime can result in lost revenue, damaged trust, and data exposure. A good recovery strategy ensures that when your primary systems fail, you have a clear path to restore operations quickly and minimize disruption and business impact.
To be transparent, we were also affected by the AWS outage. AWS is one of our key providers. However, because we have systems on other platforms and strategies in place, we were able to navigate it without a significant impact on our business.
Building safeguards starts with redundancy — distributing workloads across regions, providers, and availability zones so no single failure can take you down. It can even be as simple as moving your main AWS region away from US-EAST-1.
Here are some other strategies to consider:
- Combine automated backups with regular failover testing to ensure optimal system uptime.
- Document your recovery playbook so your team isn’t scrambling in the dark.
- Implement real-time monitoring, alerting, and security protocols that detect minor issues before they escalate into major problems.
- Put expiration dates on decisions (especially automated ones) to make sure that it’s still the correct choice (long after you forget that you made the decision in the first place).
No system is immune to failure. That means that as exponential technologies power more of our world, mistakes and outages will happen (probably more often than they do now).
You can’t prevent every outage, but you can dramatically increase the odds that it’s a manageable inconvenience, rather than a potential catastrophe.
What safeguards are you putting in place today?
Hope that helps.