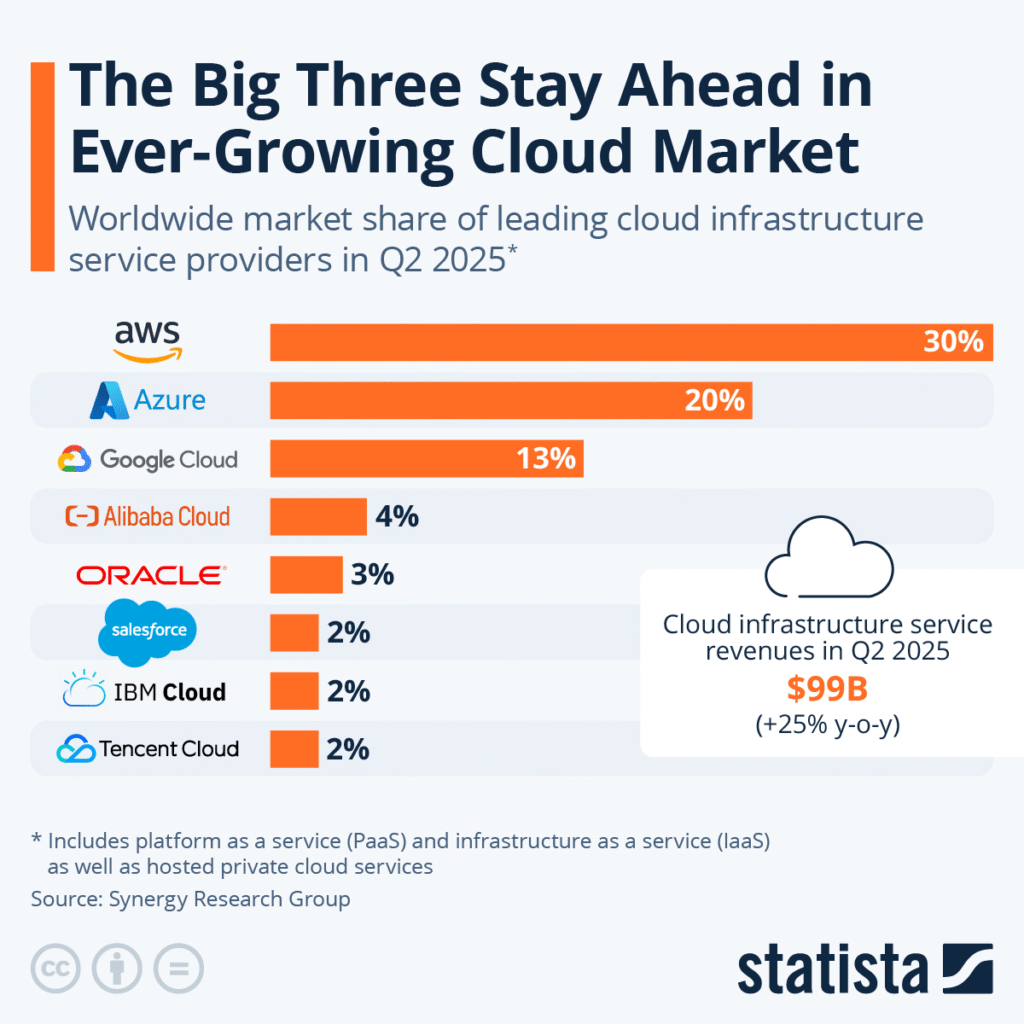
As OpenAI shifts toward a platform-based model and prepares for a future IPO, it feels like we are at a transformative moment for both the company and the broader AI industry.
At their recent DevDay 2025 event, OpenAI unveiled a range of new tools and upgrades, including:
- Apps in ChatGPT – Developers can now build and integrate apps directly in ChatGPT using a new SDK
- AgentKit – a new toolkit to build production-grade AI agents
- New and Cheaper Models, and
- Codex updates – their AI coding/developer assistant model is now out of preview and integrated with enterprise controls.
These new tools signal more than incremental upgrades — they foreshadow OpenAI’s evolution into a technology platform with the capacity to shape industries well beyond artificial intelligence.
If you‘ve paid attention, this is a big concept within my Technology Adoption Model. The four base stages of this framework are: Capability, Prototype, Product, and Platform.
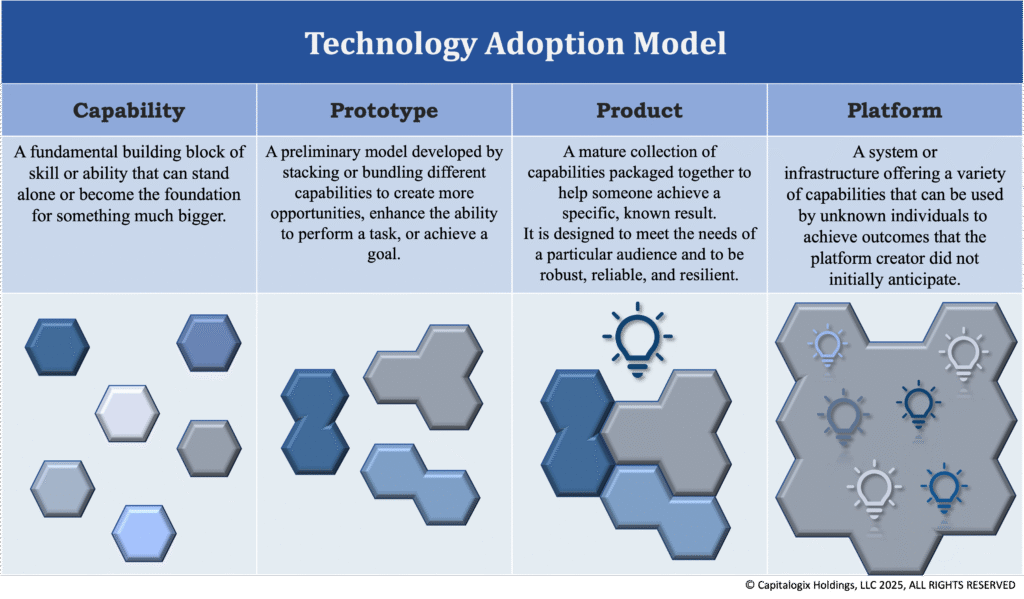
While the stages of the Technology Adoption Model Framework are important, the key point is that you don’t need to predict what’s coming; you just need to understand how human nature responds to the capabilities in front of them.
Desire fuels attention, talent, opportunities, and commerce. As money starts to flow, the path forward is relatively easy to imagine. As public interest and investment in advanced AI grow, opportunities for innovation and commercial breakthroughs become more accessible.
This model is fractal. It works on many levels of magnification or iteration.
What initially appears to be a Product is later revealed as a Prototype for something larger.
Likewise, as a Product transforms into a Platform, it becomes almost like an industry of its own. Consequently, it becomes the seed for a new set of Capabilities, Prototypes, and Products.
With OpenAI’s shift from product to platform, it’s unsurprising that both its infrastructure and corporate structure are evolving to meet new needs.
OpenAI’s Eventual IPO
On Tuesday, OpenAI announced the completion of a corporate restructuring that simplified its structure into a controlling non-profit entity and a reimagined for-profit subsidiary.
The umbrella non-profit organization will be rebranded as the OpenAI Foundation, and the for-profit entity will be called the OpenAI Group. The goal is likely to IPO before 2027.
The OpenAI Foundation organization will receive a 26% stake in the OpenAI Group, a share that would be worth $130 billion at the early-October valuation.
For now, the for-profit’s board will consist solely of the non-profit’s board members. However, the shift will enable investors and partners to more easily generate returns from their investments, paving the way for a potential public offering.
Sam Altman says they are committed to spending roughly $1.4 trillion on the chips and data centers needed to train and power their artificial intelligence systems.
The Former Non-Profit
When OpenAI launched in 2015, many were enamored with the non-profit status and its mission to ensure that artificial general intelligence (AGI) benefits all of humanity. That status was proof of a clear mission and a focus on helping humanity, rather than harming it in the pursuit of short-term profits.
This shift from the original mission has some worried about a new potential mission, weakened oversight, and increased risk, especially considering how much more powerful AGI is today compared to 10 years ago.
Like it or not, the hybrid model was the only “reasonable” path forward, since they decided to compete in this AGI race. If they fully abandoned their non-profit status, they would have had to buy their non-profit’s assets for “fair market value”, which likely would have meant a $500 billion price tag.
Meanwhile, companies like Google DeepMind, Microsoft, Amazon, Anthropic, and Mistral AI are already for-profit entities making massive strides (not to mention, Microsoft has invested billions into OpenAI, and will be receiving a 27% stake in the OpenAI Group).
Where OpenAI is Today
While it’s fun to think about the future – and what the restructuring will do for investment and innovation, it also helps to understand their current infrastructure.
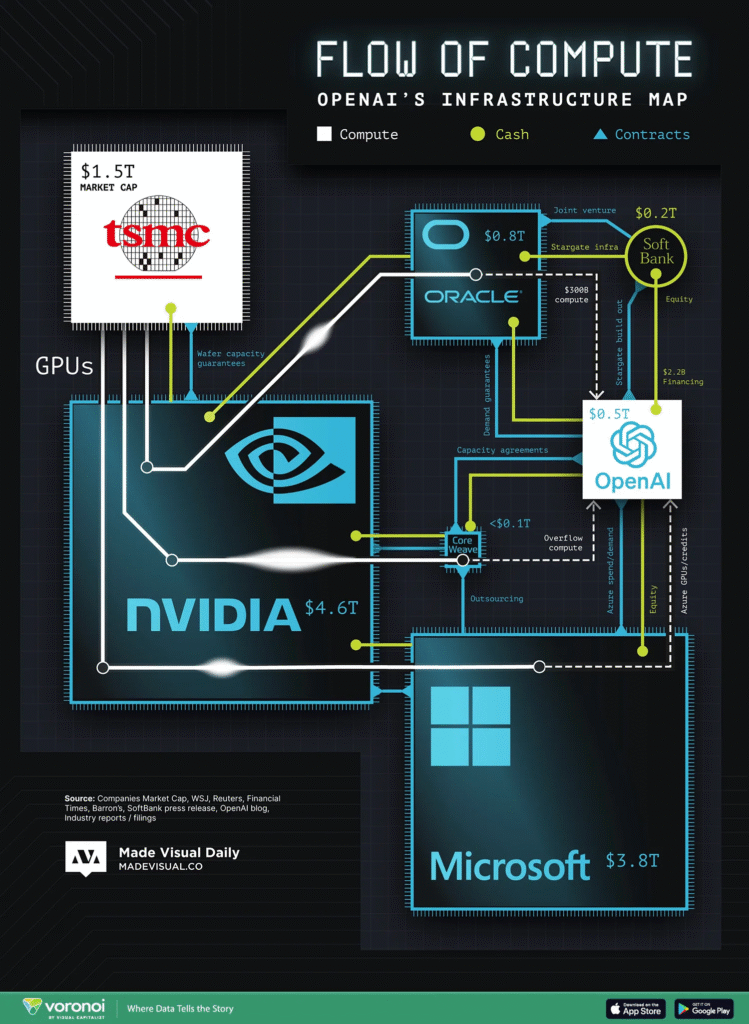
via visualcapitalist
OpenAI has spawned a large, networked ecosystem comprising numerous major organizations, complex contracts, and substantial financial investments.
The chart above shows three separate flows: compute, cash, and contracts.
The biggest nodes in the diagram should look familiar. Microsoft not only provides compute through Azure, but also has invested capital and GPU credits back into OpenAI. Nvidia (now worth ~ $5 trillion) not only provides the mass majority of the GPUs to OpenAI, but accounts for around 16% of America’s current GDP,
Nvidia continues to dominate the semiconductor industry, with a market valuation nearly three times higher than its closest U.S. competitor, even as OpenAI begins to partner more deeply with AMD.
GPUs, Datacenters, and AGI, Oh My!
While OpenAI’s leadership and strategic partnerships are crucial, their future progress relies heavily on access to an increasing amount of advanced GPUs (Graphics Processing Units) — arguably the most strategic resource in today’s AI landscape.
But, GPUs are costly. Demand often outstrips supply, and their production depends on cutting-edge manufacturing. Consequently, the supply chain remains fragile due to limited materials, as well as geopolitical and logistical issues that could send shockwaves throughout the entire sector.
Demand has grown so intense that businesses are reserving capacity months or even years in advance. In rare cases, some even use GPUs as collateral to secure financing, reinforcing their role as a new strategic commodity.
Data centers — the facilities that house and power those GPUs — are also costly. They require substantial amounts of electricity, cooling, physical space, and high-speed networking to support AI workloads.
Together, these costs make scaling AI models (like those from OpenAI) very expensive. Even if OpenAI can build smarter models, it’s limited by the number of GPUs and data centers it can access or afford, creating a bottleneck in growth and deployment.
So, while some people are upset about this transition away from their non-profit status, I think it was inevitable and predictable.
We’re at a turning point in artificial intelligence as a whole.
OpenAI’s switch marks a clear swing in the pendulum. For users, businesses, and developers, it means faster innovation, better products, and a clearer path toward scaling powerful AI (we hope responsibly).
That said, there are still real challenges ahead. Finding equilibrium between commercial interests and mission-driven goals is challenging. Likewise, even well-intentioned oversight can strain under market pressures. Massive infrastructure investments can create higher barriers to entry for smaller players, potentially concentrating power among a few large companies. And while OpenAI’s scale and resources set it up for breakthroughs, they don’t guarantee them—execution, safety, and responsible deployment remain critical.
In short, OpenAI’s impending IPO and platform pivot mark a defining moment in AI history. While its scale and investment signal immense opportunities, they also invite crucial scrutiny. The road ahead will depend on how OpenAI manages the delicate balance between rapid innovation, financial pressures, and the broader public good. As this story unfolds, what happens next will shape the very fabric of our technological future.
Onwards!